Aparecium
An XQuery / XSLT library for invisible XML
C. M. Sperberg-McQueen, Black Mesa Technologies LLC
5 November 2021
http://blackmesatech.com/2021/11/Aparecium/
Overview
- What is it?
- invisible XML?
- Aparecium?
- How do I use it?
- How does it work?
- Earley parsing
- Extended BNF
- Ambiguity
- Speed
- What now?
What is it?
- What is invisible XML?
- What is Aparecium?
Invisible XML
Steven Pemberton (2013) at Balisage:
“a method for treating non-XML documents
as if they were XML”
Combines two ideas:
- Documents have (information in general has) structure worth exposing to software.
- Non-XML resources often have implicit structure.
Two audiences:
- Authors can work in non-XML notations.
- XSLT / XQuery programmars can read and process non-XML resources.
Example: Natural language
“Sarah laughed.”

Example (2): Natural language
“The cows on the hill ate grass.”
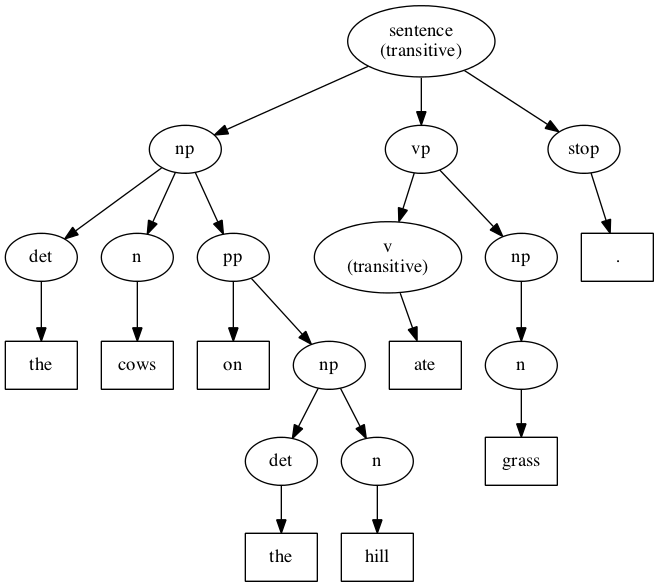
Example (2b): Natural language
“The cows on the hill ate grass.”
<transitive-sentence>
<np>
<det>the</det>
<n>cows</n>
<pp>
<prep>on</prep>
<np>
<det>the</det>
<n>hill</n>
</np>
</pp>
</np>
<vp-t>
<v-t>ate</v-t>
<np>
<n>grass</n>
</np>
</vp-t>
<stop>.</stop>
</transitive-sentence> Example (3): Artificial language
CSS as I write it:
td {
vertical-align: top;
}
img {
text-align: center;
}CSS as I might want to process it:
<css>
<rule selector="td">
<property name="vertical-align" value="top"/>
</rule>
<rule selector="img">
<property name="text-align" value="center"/>
</rule>
</css>Aparecium
Hermione was pulling her wand out of her bag.‘It might be invisible ink!’ she whispered.She tapped the diary three times and said, ‘Aparecium!’-J. K. Rowling, Harry Potter and the Chamber of Secrets
- proof of concept implementation
- for use in XSLT* and XQuery
- basic idea:
- Like doc(), only for non-XML data.
- Like unparsed-data(), only it returns a document.
Show and tell
The easiest way to learn about invisible XML
is by example.
Demo:
- list of numbers
- s-expressions
- arithmetic expressions
- grammar notation
- hiding nonterminals, terminals
- attributes or elements
Some notes
- proof of concept, not industrial code
- (he means: it's slow and not well debugged)
- (I mean, like, really kind of slow ...)
- (sooooooo slow ...)
How do I use it?
- prerequisites:
- XQuery engine
- input
- grammar
- Using Aparecium:
- import the module
- read the grammar and the input
- parse the string
No restrictions
Invisible XML specifies notation but does not restrict the grammar.
- It need not be LL(1).
- It need not be LL(k).
- It need not be LALR(1).
- It need not be unambiguous.
Any context-free grammar is accepted.
Show and tell, again
Demo: look at the code
- aparecium:parse-string()
- aparecium:compile-grammar-from-string()
- aparecium:parse-string-with-compiled-grammar()
How does it work?
- Earley parsing
- Extended BNF
- Ambiguity
- Speed
Earley parsing
Consider parsing a string (“Sarah laughed”) against a
grammar:
-sentence: transitive-sentence; intransitive-sentence.
transitive-sentence: np, vp-t, stop.
intransitive-sentence: np, vp-i, stop.
np: pn; det?, n, pp*; pron.
vp-t: v-t, np, pp*.
vp-i: v-i, pp*.
pp: prep, np.
Earley parsing (2)
- We need a sentence (starting at offset 0).
- So we need either a transitive-sentence or an intransitive-sentence.
Recursive-descent parsing requires that we know
which we want, now, without looking further.
Earley parsing tries both:
- Look for a transitive-sentence starting at 0.
- Look for an intransitive-sentence starting at 0.
- So, look for an np starting at 0.
- Look for a pn starting at 0.
- Look for a det starting at 0.
- Look for an n starting at 0.
- Look for a pron starting at 0.
Earley parsing (3)
- Look for any of “Sam”, “Sarah”, ... starting at 0.
- Win: we found “Sarah” starting at 0.
- ...
- So look for a vp starting at 6.
- Look for any of “the”, “some”, ... starting at 0. (... nope)
- Look for any of “cows”, “plant”, “grass”, “people”, “telescope”, “hill” ... starting at 0. (... nope)
- Look for any of “you”, “we”, ... starting at 0. (... nope)
Earley parsing (in a nutshell)
- Try everything that could possibly succeed.(Differs here from many parsing methods.)
- Try nothing that is not known to be relevant.(Differs from CYK and some other general methods here.)
- Keep track of what you try, using Earley items: (from-position in input, to-position in input, rule, position in rule).When you generate the item (0, length, Goal, final), you're done. Construct a tree from the set of items.
Extended BNF
Earley uses BNF; we use EBNF.
Position in a BNF rule is simple, can be just a number from 0 to
length of rule.
Two approaches:
- Compile EBNF rules to (recursive) BNF.
- Extend notion of rule position.
Aparecium takes second approach.
Compiling the grammar (1)
Each rule in an iXML (EBNF) grammar is a regular expression:
- symbol (non-terminal or terminal)
- E?
- E*
- E+
- E*F (zero or more E, separated by F)
- E+F (one or more E, separated by F)
- (E)
Compiling the grammar (2)
Brüggemann-Klein 1993 shows (following Gluschkov) how
to make an FSA from a regular expression (in quadratic time):
- Let states be the primitive symbols of the RE.
- For each sub-expression E, calculate
(bottom up)
- first(E) (initial states of E)
- last(E) (final states of E)
- for each state q in E,
and each symbol s in alphabet,
also
follow(q, s, E) (transitions in q within E)
Compiling the grammar (3)
For example:
expression: term, (s, addop, s, term)*.
This produces

The compiled rule
The compiled rule
- assigns an ID to each symbol (state)
- decorates each expression with first,
last, nullable, and
follow:* attributes.
Aparecium needs the ones on the outermost definition.
<rule name="expression"
xmlns:follow="http://example.com/followset">
<def xml:id="exp_def_1"
nullable="false"
first="term_1"
last="term_1 term_2"
follow:term_1=" s_1"
follow:s_1=" addop_1"
follow:addop_1=" s_2"
follow:s_2=" term_2"
follow:term_2="s_1">
...
</def>
</rule>
Ambiguity
The iXML spec returns one tree; in case of
ambiguity, signal that there are others.
Aparecium wants to return all trees
(to help debug the grammar).
Ambiguity (2)
But ... some languages are infinitely ambiguous:
- A: A; "a".Unbounded depth (‘vertically infinite’):
- <A>a</A>
- <A><A>a</A></A>
- <A><A><A>a</A></A></A>
- ...
- S: X*.
X: "x"; {nothing}.Unbounded width (‘horizontally infinite’). Parses for the empty string include:- <S><X/></S>
- <S><X/><X/></S>
- <S><X/><X/><X/></S>
- ...
Ambiguity (3)
Handling infinite ambiguity:
-
Loop detection.
- <A>a</A>
- <S><X/></S>
-
Parse-forest grammars (grammatical representation of parse tree).
- A: A_0_1.
A_0_1: A_0_1; "a". - S: S_0_0.
S_0_0: X_0_0*.
X_0_0: {nothing}.
- A: A_0_1.
Ambiguity (4)
Demo:
- PP attachment ambiguity: “the cows eat the grass on the hill”.
- infinite tree sets
- S: S; 'a'.
- S: X*. X: 'x'; {}.
Representation of Earley items
- As element:
<item from="0" to="20" ri="term_2"> <rule name="expression"> ... </rule> </item> - As map:
map { 'from' : $From, 'to' : $To, 'rule' : $r, 'ri' : $ri }
Performance
Earley parsing creates a lot of
Earley items:
at least one per character.
at least one per character.
What would you do?
What I did
- Changing representation of items (elements to maps) improved run time by 15-30%.
- Changing representation of set from sequence to map improved run time by 6-10×.
Measure first. (D'oh!)
The major time cost was not constructing Earley items
but finding them in the set.
What now?
- mention related work
- plans
Related work
- Invisible XML:
- XML::Invisible Perl package (“Ed J”)
- Functional invisible XML parser (John Snelson)
- Earley parsers in ABC, C (Steven Pemberton)
- Jay Parser (Tom Hillman)
- Parsing in XSLT, XQuery:
- REx (Gunther Rademacher)
- FXSLT LR-1 parser (Dimitre Novatchev)
- Exposing non-XML resources in XML (‘XML lenses’):
- DFDL Data Format Definition Language (Open Grid Forum)
- Data Direct Connectors
- Regular fragmentation (Simon St. Laurent 2001)
- STnG (Ari Krupnikov 2003)
What next?
- Move from proof of concept to practical tool
- Release engineering
- Speed improvements
- Better error reporting / recovery
- Easier use
- Grammar repository for standard notations (CSS, JSON, XPath, XPointer, ...)
- Automatic selection of grammar based on MIME type?
- Grammar analysis tools
- Is the grammar ambiguous?
- Is the grammar LL(1)? LALR(1)? ...
- Is a recursive descent parser possible? Would it be faster?
- ...
- Sample applications
Thanks
Thank you.
Any questions?