Document modeling
Descriptive markup, SGML, XML
C. M. Sperberg-McQueen, Black Mesa Technologies LLC
Rev. 11 September 2012
Nearby documents
Overview
- Organizational notes
- Specimen problems in document representation
- Two vocabularies
- Bare-bones TEI
- text/richtext, text/enriched
- Models of XML
- character stream
- sequence of character sequences
- tree
- Document object model
- XML information set
- XPath 1.0
- XDM (XPath 2.0, XQuery 1.0 data model)
- directed graph
Organizational notes
Bureaucracy, paperwork, and so on ...
Discussion logs
The syllabus says your work will include:
- (once or twice during the semester) preparation of a summary of the discussion in a class session
Sign up!
On the spot for today: Ryan Buller. Ready?
Vocabulary introductions
The syllabus says your work will include:
- (once during the semester) a class presentation on an important XML vocablary; you will be responsible for doing the necessary preparation, briefing the class on the origin and goals of the vocabulary, and providing a page with links to the defining documents for the vocabulary, the schema(s) for the vocabulary, and available documentation. If you are particularly energetic, you may also prepare to show the class how the vocabulary addresses the various concrete document-modeling and design questions we will ask about each vocabulary we look at.
Sign up!
Any volunteer for ISO 8879 Annex E (next week)?
Any requests for additional vocabularies?
Submission of XML documents
It's easier for me if you submit XML documents in XML form
(i.e. not in Word or RTF).
It's probably easier for you, too: XML
was designed to be editable without software help,
but software help does make it more convenient!
[Brief pause to demo Oxygen ...]
If you run into trouble, ask for help on the forum!
Questions from last week?
Anything we need to clear up before proceeding?
Notes from last week's homework
Some points to clear up:
- No two attributes on any element can have the same name. So <name type="nickname" type="collective">Copperheads</name> is not well formed.
- Each element must close. So <name>...<name> is not well formed.
- Attributes take the form name = "value" or name = 'value' (white space around = is optional). So <div="3">...</div> and <id-number="3.141592"/ are not well formed.
- XML uses ASCII quotation marks, not curly quotes. So <name type=“personal”>...</name> is not well formed.
Document representation
Some questions to think about ...
Descriptive markup
- sections and headings
- lists, paragraphs, and notes
- phrase-level elements
- direct discourse and quotation
- poetry, drama
- textual variation
- annotation
- dates and other low-level datatypes
- metadata — inline? external?
Sections and headings
Does the vocabulary have markup for
sections?
For section headings?
Do all sections have headings?
Example 1: Sections and headings
Flat sequence of headings and paragraphs:
<h1>Part I: Description</h1> <h2>Introduction</h2> <p><label>0.21</label> Lorem ipsum dolor sit amet, ...</p> <p><label>0.22</label> At vero eos et accusam et justo ...</p> <h3>Structure of Part I</h3> <p><label>0.23</label> Stet clita kasd gubergren, ...</p> <h4>Methods of Procedure</h4> <p><label>0.24</label> Duis autem vel eum ...</p> <h4>Options and Omissions</h4> <p><label>0.26</label> Vel illum dolore eu feugiat nulla facilisis at vero eros et accumsan ...</p> <h2>1 General Rules for Description</h2> <h3>1.0 General Rules</h3> <p><label>10A. Sources of information</label></p> <p><label>1.0A1.</label> Each chapter ...</p> <p><label>1.0A2. Items lacking a chief source of information.</label> If no part of the item .. </p> <p>Ut wisi enim ad minim veniam, ...</p> <p>Nam liber tempor cum soluta nobis ...</p> ... <h2>2 Books, Pamphlets, and Printed Sheets</h2> <p>...</p> ... <h2>12 Serials</h2> <p>...</p> <h2>13 Analysis</h2> <p>...</p> ... <h1>Part II: Headings, Uniform Titles, and References</h1> <h2>Introduction</h2> <p>...</p> <h2>21 Choice of Access Points</h2> <p>...</p> <h2>22 Headings for Persons</h2> <p>...</p>
Example 2: Sections and headings
Distinct section types:
<part>
<head>Part I: Description </head>
<chapter>
<head>Introduction</head>
<p><label>0.21</label> Lorem ipsum dolor sit amet, ...</p>
<p><label>0.22</label> At vero eos et accusam et justo ...</p>
<section>
<head>Structure of Part I</head>
<p><label>0.23</label> Stet clita kasd gubergren, ...</p>
</section>
<section>
<head>Methods of Procedure</head>
<p><label>0.24</label> Duis autem vel eum ...</p>
</section>
<section>
<head>Options and Omissions</head>
<p><label>0.26</label> Vel illum dolore eu feugiat
nulla facilisis at vero eros et accumsan ...</p>
</section>
</chapter>
<chapter>
<head>1 General Rules for Description</head>
<section>
<head>1.0 General Rules</head>
<subsection>
<p><label>10A. Sources of information</label></p>
<p><label>1.0A1.</label> Each chapter ...</p>
<p><label>1.0A2. Items lacking a chief source of information.</label>
If no part of the item ..
</p>
<p>Ut wisi enim ad minim veniam, ...</p>
<p>Nam liber tempor cum soluta nobis ...</p>
</subsection>
</section>
...
</chapter>
<chapter>
<head>2 Books, Pamphlets, and Printed Sheets</head>
<p>...</p>
</chapter>
...
<chapter><head>Serials</head><p>...</p></chapter>
<chapter><head>Analysis</head><p>...</p></chapter>
</part>
<part>
<head>Part II: Headings, Uniform Titles, and References</head>
<chapter>
<head>Introduction</head>
<p>...</p>
</chapter>
<chapter>
<head>Choice of Access Points</head>
<p>...</p>
</chapter>
<chapter>
<head>Headings for Persons</head>
<p>...</p>
</chapter>
</part>
Example 3: Sections and headings
Distinct but generic section types:
*-->
<div1>
<head>Part I: Description </head>
<div2>
<head>Introduction</head>
<p><label>0.21</label> Lorem ipsum dolor sit amet, ...</p>
<p><label>0.22</label> At vero eos et accusam et justo ...</p>
<div3>
<head>Structure of Part I</head>
<p><label>0.23</label> Stet clita kasd gubergren, ...</p>
</div3>
<div3>
<head>Methods of Procedure</head>
<p><label>0.24</label> Duis autem vel eum ...</p>
</div3>
<div3>
<head>Options and Omissions</head>
<p><label>0.26</label> Vel illum dolore eu feugiat
nulla facilisis at vero eros et accumsan ...</p>
</div3>
</div2>
<div2>
<head>1 General Rules for Description</head>
<div3>
<head>1.0 General Rules</head>
<div4>
<p><label>10A. Sources of information</label></p>
<p><label>1.0A1.</label> Each chapter ...</p>
<p><label>1.0A2. Items lacking a chief source of information.</label>
If no part of the item ..
</p>
<p>Ut wisi enim ad minim veniam, ...</p>
<p>Nam liber tempor cum soluta nobis ...</p>
</div4>
</div3>
...
</div2>
<div2>
<head>2 Books, Pamphlets, and Printed Sheets</head>
<p>...</p>
</div2>
...
<div2><head>Serials</head><p>...</p></div2>
<div2><head>Analysis</head><p>...</p></div2>
</div1>
<div1>
<head>Part II: Headings, Uniform Titles, and References</head>
<div2>
<head>Introduction</head>
<p>...</p>
</div2>
<div2>
<head>Choice of Access Points</head>
<p>...</p>
</div2>
<div2>
<head>Headings for Persons</head>
<p>...</p>
</div2>
</div1>
<!--* Example 4: Sections and headings
Generic (self-nesting) sections:
<div>
<head>Part I: Description </head>
<div>
<head>Introduction</head>
<p><label>0.21</label> Lorem ipsum dolor sit amet, ...</p>
<p><label>0.22</label> At vero eos et accusam et justo ...</p>
<div>
<head>Structure of Part I</head>
<p><label>0.23</label> Stet clita kasd gubergren, ...</p>
</div>
<div>
<head>Methods of Procedure</head>
<p><label>0.24</label> Duis autem vel eum ...</p>
</div>
<div>
<head>Options and Omissions</head>
<p><label>0.26</label> Vel illum dolore eu feugiat
nulla facilisis at vero eros et accumsan ...</p>
</div>
</div>
<div>
<head>1 General Rules for Description</head>
<div>
<head>1.0 General Rules</head>
<div>
<p><label>10A. Sources of information</label></p>
<p><label>1.0A1.</label> Each chapter ...</p>
<p><label>1.0A2. Items lacking a chief source of information.</label>
If no part of the item ..
</p>
<p>Ut wisi enim ad minim veniam, ...</p>
<p>Nam liber tempor cum soluta nobis ...</p>
</div>
</div>
...
</div>
<div>
<head>2 Books, Pamphlets, and Printed Sheets</head>
<p>...</p>
</div>
...
<div><head>Serials</head><p>...</p></div>
<div><head>Analysis</head><p>...</p></div>
</div>
<div>
<head>Part II: Headings, Uniform Titles, and References</head>
<div>
<head>Introduction</head>
<p>...</p>
</div>
<div>
<head>Choice of Access Points</head>
<p>...</p>
</div>
<div>
<head>Headings for Persons</head>
<p>...</p>
</div>
</div>
Lists, paragraphs, and notes
Does the vocabulary have markup for
lists? paragraphs? footnotes? endnotes?
block notes?
Can lists occur between paragraphs?
Can lists occur within paragraphs?
Do paragraphs occur within list items?
Ditto for notes.
Example 1: lists and paragraphs
A list item contains character data and
phrase-level elements.
<p>Here we are.
<list>
<item>And here's a list.</item>
<item>Each item is <emph>just like</emph>
a paragraph.</item>
</list>
Note that the list itself is inside a paragraph.
</p>Example 2: lists and paragraphs
A list item sometimes contains character
data or paragraphs:
<p>Here we are.
<list>
<item>And here's a list.</item>
<item>Each item is a paragraph.</item>
<item>
<p>Or possibly several paragraphs.</p>
<p>After all, list items can sometimes
contain several paragraphs.</p>
</item>
<item>Sometimes the first paragraph in a
list item is special (and doesn't need
a paragraph tag).
<p>Sometimes not.</p>
</item>
</list>
Note that the list is inside a paragraph.
</p>
Example 3: lists and paragraphs
Or does a list item contain
only explicitly tagged
paragraphs?
<p>Here we are.</p>
<list>
<item><p>And here's a list.</p></item>
<item><p>Each item is a paragraph.</p>
<p>List items don't contain PCDATA directly:
instead, each list item consists of
one or more paragraphs (or similar
container elements).</p>
</item>
</list>
<p>Note that the list is <emph>not</emph>
inside a paragraph!</p>
Phrase-level elements
What sort of character- or phrase-level markup
is allowed? (If something is italic, can I say
why it's italic? Must I?)
Direct discourse and quotation
Does the vocabulary have markup for
run-on quotations? block quotations?
Can they be used for direct discourse in narrative?
Poetry, drama
Does the vocabulary have markup for
verse? drama?
Textual variation
What happens if I must record different
readings in different sources of the work?
Annotation
Does the vocabulary support
arbitrary annotation of the document?
Annotation of fixed types?
Hypertext
Does the vocabulary support
hyperlinking?
Outgoing?
Incoming?
Dates and other low-level datatypes
Does the vocabulary have markup for
dates? numbers? weights and measures? times of day?
URIs?
Metadata — inline? external?
Does the vocabulary allow the XML document to
identify itself using internal metadata?
External metadata?
A sample vocabulary
The first of many ...
Bare-bones TEI
Documentation:
http://cmsmcq.com/1994/bb/teiu6.xml
A very very small subset of the TEI vocabulary.
Another sample vocabulary
Hand off to Megan Tynan
for intro to text/richtext, text/enriched ...
XML models
Some questions to think about ...
What is an XML document?
What does the spec say?
The XML spec says:
A data object is an XML document if it is well-formed, as defined in this specification. In addition, the XML document is valid if it meets certain further constraints.
So XML documents are a subset of
“data objects”? Thanks a lot, ...
Several views of XML
What is an XML document?
Possible answers:
- a sequence of characters
- a sequence of
- parsed character data
- tag
- comment
- processing instruction
- a tree
- a directed graph
Characters
What is a character?
In punched cards, one of
“&-0123456789ABCDEFGHIJKLMNOPQR/STUVWXYZ”
In computers, it depends.
Historically important coded character sets include:
- ANSI X3.4 American Standard Code for Information Interchange (ASCII) (1963, 1967, 1986)
- ISO/IEC 646:1991 Information technology — ISO 7-bit coded character set for information interchange (1972, 1991)
- ANSI/NISO Z39.47 American National Standard for Extended Latin Alphabet Coded Character Set for Bibliographic Use (ANSEL) (1985, 1993)
- ISO/IEC 6937:2001 Information technology — Coded graphic character set for text communication — Latin alphabet (1983, 2001)
- ISO/IEC 8859-1 ... -15 8-bit single-byte coded graphic character sets, Part 1: Latin alphabet No. 1 (etc.) (1987, ...)
Today,
- ISO/IEC 10646 Information technology — Universal multiple-octet coded character set (UCS) (1993, 2000, 2001, 2003, 2011)
- Unicode
Sequences
What is a sequence?
An “ordered list of objects”.
Like a set: contains members (aka elements, terms).
Unlike a set: ordered, elements can appear twice.
Formalizing sequences
Two formalizations:
(1) objects with two operations: what-is-this? and get-next.
For example: a → b → a → b
Or:
* --> * --> * --> * | | | | a b a b
(2) a relation mapping a prefix of the natural numbers to a set of objects.
E.g. {1 → a, 2 → b, 3 → a, 4 → b}
Trees
What is a tree?
Informally,
a tree is a collection of nodes connected into a structure.
- One node has no parent: the root.
- All other nodes have exactly one parent each.
- If x is parent of y, then y is child of x.
- Some nodes have no children: the leaves.
Trees
What is a tree?
More formally (Aho, Hopcroft, and Ullman,
Data structures and algorithms):
- A single node by itself is tree. This node is also the root of the tree.
- Suppose n is a node and T1, T2, Tk are trees with roots n1, n2, nk, respectively. We can construct a new tree by making n be the parent of nodes n1, n2, nk. In this tree n is the root and T1, T2, Tk are the subtrees of the root. Nodes n be the parent of nodes n1, n2, nk are called the children of node n.
Example 1: trees
Example 2: trees
Trees and XML
A document is a collection of nodes connected into a structure.
- Each node is an element, or a text node, or a comment, or a processing instruction.
- One element has no parent: the root.
- All other nodes have exactly one parent each.
- Elements may have children; comments, text nodes, and processing instructions are all leaves and have no children.
Trees
What is a tree?
For XML the document is an
ordered tree:
the children of each parent are ordered.
Directed graphs / Digraphs
What is a graph? A directed graph?
A directed graph D is
- a set V(D) of vertices
- a set (or family*) A(D) of ordered pairs (v, w) of elements of V(D), called arcs
Note that any tree is also a digraph.
* A 'family' allows multiples (aka 'bag').
Specifications
What do the specs say?
The specs say “yes”.
- XML spec
- Document object model (DOM)
- XML information set (infoset)
- XPath 1.0 data model
- XPath 2.0 and XQuery 1.0 data model (XDM)
The Document Object Model (DOM): XML as object
See the spec.
Aligned with HTML DOM.
Complete specification of (abstract) API.
The XML information set: XML as information
See the spec.
The XPath data model: XML as tree
An attempt to abstract away from XML syntax.
Initially (1999) just a section of the XPath 1.0 spec.
Later, a free-standing spec of its own, hugely elaborated.
XDM (XPath/XQuery data model)
The XPath data model (revisited)
- A tree is a set of nodes.
- Every node but one has a parent node.
- Nodes with the same parent are totally ordered.
So we have two crucial relations:
dominance (or: containment),
sequence (or: linear precedence).
Two kinds of linear precedence
Two concepts of tree:
- a set of elements, each element containing its children and contained by its parent
- a set of nodes with a parent/child relation
Ordering clear vis-a-vis siblings, cousins, etc.
But — does a parent precede a child?
In a node-oriented view, it's natural to say that a parent
node precedes a child node; the total ordering of nodes in the
tree is then the visit order in a pre-order traversal.
It's less natural, though, to say that line 1 of Sonnet 92 is
preceded by Sonnet 92 in the text of Shakespeare's sonnets.
Some readers will insist that, on the contrary, line 1 cannot either
precede or follow Sonnet 92, because the line is contained within the
sonnet.
Element order is a subset of node order.
The treatment of order in XDM is a compromise between these
views.
XDM as abstraction from XML
XDM's formal definition is independent of XML.
Anything can instantiate XDM, if:
- We have a set S and two relations Q and R on S.
- Q and R are functional and acyclic.
- ∀ s1, s2 ∈ S (s1 R s2 ⇒ ∃ s3 ∈ S (s1 Q s3 ∧ s2 Q s3))
- ∀ s1, s2, s3 ∈ S (s1 Q s3 ∧ s2 Q s3 ⇒ (s1 R+ s2 ∨ s1 R+ s2))
A paraphrase: parent relation
A bit more intuitively:
- We have a set S and two relations Q and R on S.The members of S we will call nodes.
- R [is] functional and acyclic.Call R the parent relation.Each node has at most one parent (R is functional). No node is its own ancestor, where ancestor = parent+ (R is acyclic).
Paraphrase (2): nextsib
- Q [is] functional and acyclic.Call Q the nextsib (immediate following sibling) relation.Every node has at most one next sibling (Q is functional), and no node is its own following sibling, where following = nextsib+ (Q is acyclic).
- ∀ s1, s2 ∈ S (s1 R s2 ⇒ ∃ s3 ∈ S (s1 Q s3 ∧ s2 Q s3))Any node and its next sibling have the same parent.
- ∀ s1, s2, s3 ∈ S (s1 Q s3 ∧ s2 Q s3 ⇒ (s1 R+ s2 ∨ s1 R+ s2))Any two children of the same parent are related by the nextsib relation (i.e. there is a chain of nextsib pairs from one to the other).
This amounts to saying:
Nodes with the same parent are totally ordered:
if x and y are siblings, then
x < y or x > y or x = y.
N.B. We are ignoring attributes, namespaces, element types,
and some other details.
Exploiting the relations
We make the model more comfortable to work with
by extending the two crucial relations in three ways:
- total document ordering
- transitive closures
- inverses
Document ordering
First, we define a total document ordering.
For any two nodes x and y,
x follows y if and only if
- x is the nextsib of y, or
- y is the parent of x, or
- x is the nextsib of some node z which is an ancestor of y, or
- there is some node z such that z follows y and x follows z
Another way to put this is:
- Preceding siblings precede following sibings (i.e. document order is compatible with the total ordering among siblings).
- Ancestors precede descendants.
- Descendants of a node precede that node's following siblings.
When we stop ignoring attribute and namespace nodes, we also
have the rules:
- The namespace nodes and attribute nodes of an element precede that element's children.
- The namespace nodes of an element precede that element's attribute nodes.
- The namespace nodes of an element are totally ordered; the order is implementation-dependent. (That is, it may vary from implementation to implementation, and may vary arbitrarily within an implementation, and implementations are not encouraged to document it.)
- The attribute nodes of an element are totally ordered; the order is implementation-dependent.
An XML tree
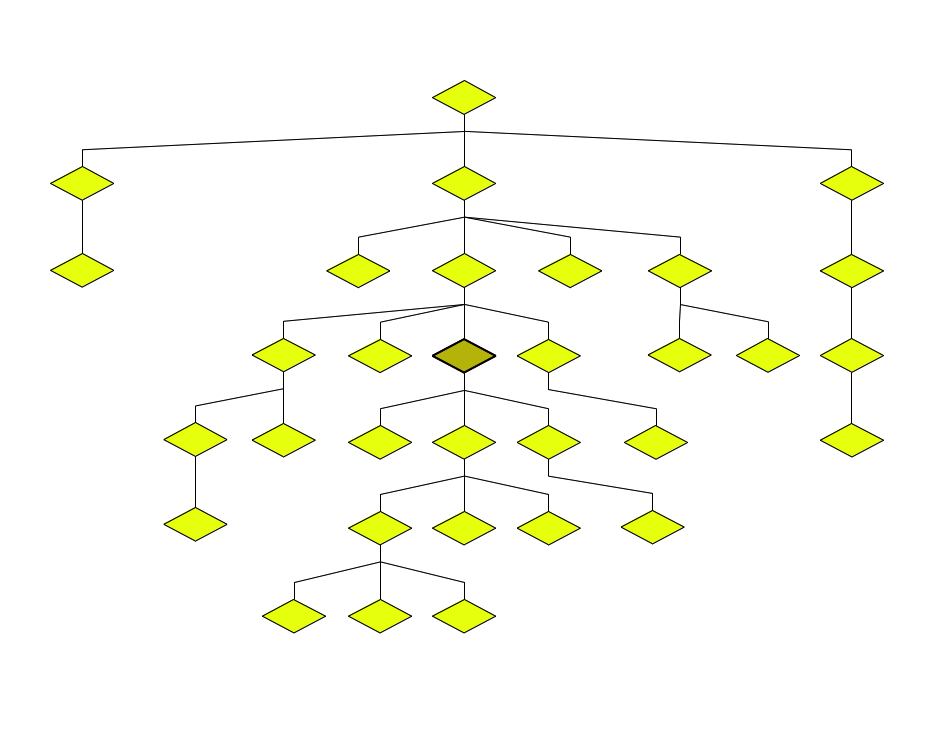
Ancestor = Parent+
The ancestor relation is the positive transitive
closure of the parent relation.
Ancestors
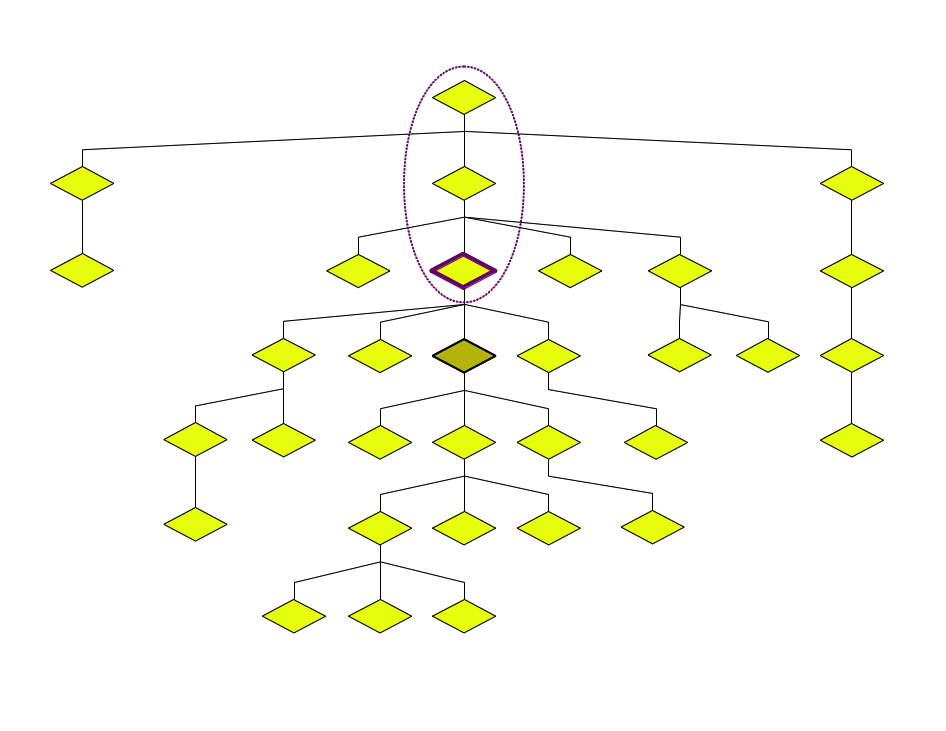
Child = Parent-1
The child relation is the inverse of
the parent relation (for element children only!).
Descendant = Child+
The descendant relation is the positive transitive
closure of the child relation.
Descendants
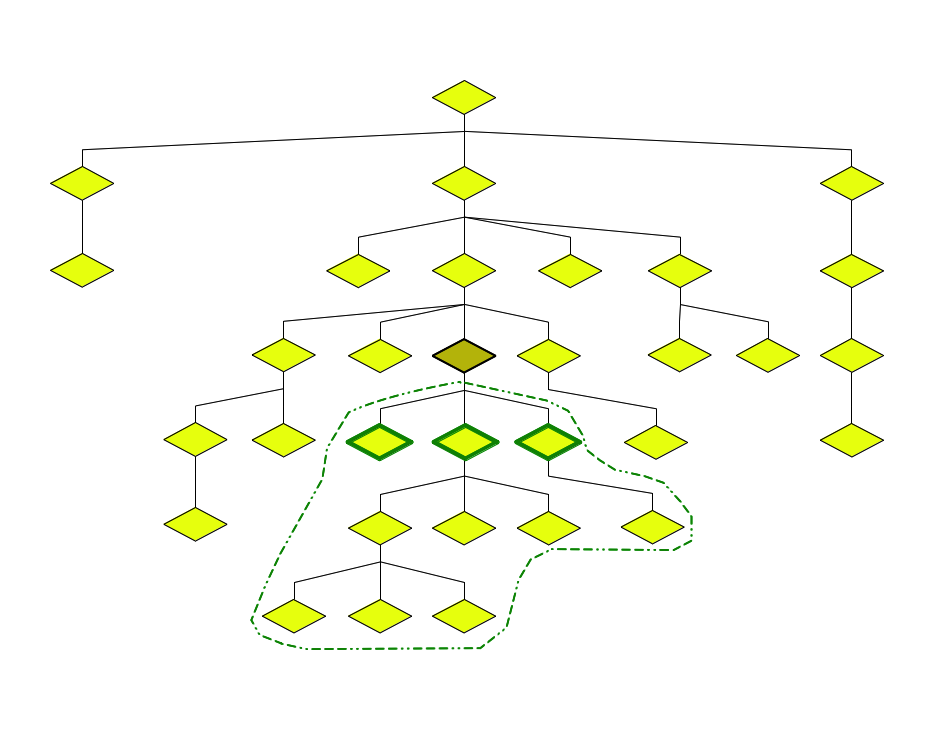
The vertical axes
Up/down
| One step | Closure | |
|---|---|---|
| Up | parent | ancestor |
| Down | child | descendant |
Linear Precedence
The following-sibling relation is the positive
transitive closure of the nextsib relation.
The prevsib relation is the inverse of the
nextsib relation.
The preceding-sibling relation is the positive
transitive closure of the prevsib relation (and also
the inverse of following-sibling).
For the following and preceding relations
see above.
Preceding
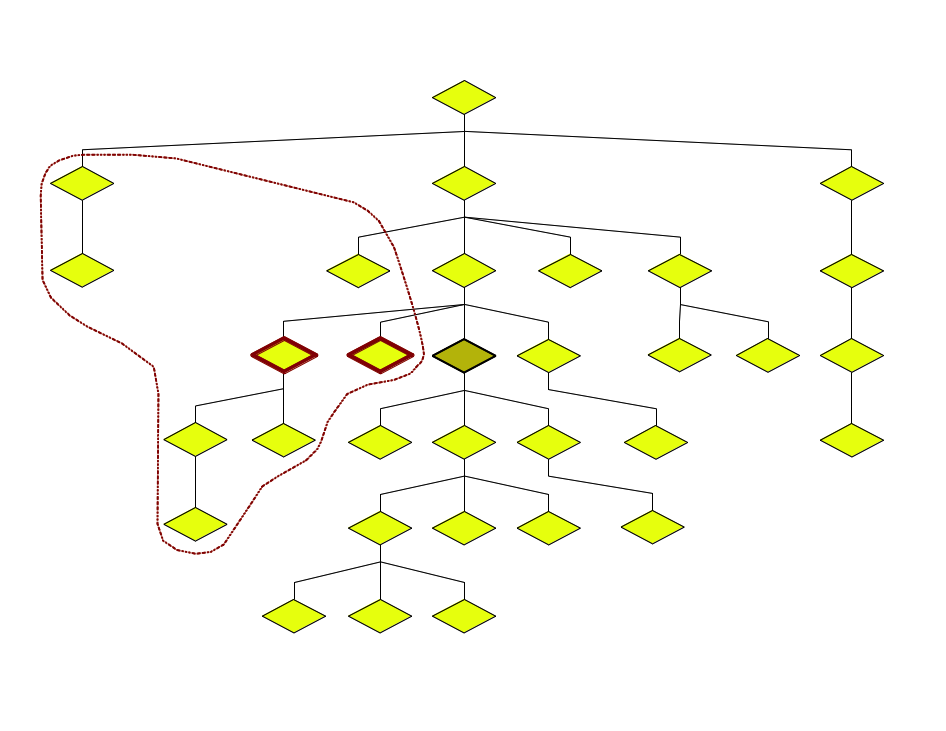
Following
Sideways axes
Sideways
| One step | Closure | |
|---|---|---|
| Toward the front / older | *previous-sibling | preceding-sibling |
| Toward the back / younger | *next-sibling | following-sibling |
Overall document order
| One step | Closure | |
|---|---|---|
| Backwards / older | *previous-node | >> |
| Forwards / younger | *next-node | << |
XPath data model, cont'd
- Every nodes is exactly one of these:
- element
- attribute
- text node
- comment
- processing instruction
- namespace node
- document
Compact summary of the XDM
- items = nodes + atomic values
- nodes = document + element + attribute + comment + processing-instruction + text + namespace
- atomic values = values of XSD simple types
- nodes arranged in trees, related by axes:
- parent, child
- ancestor, descendant
- preceding-sibling, following-sibling
- preceding, following
- total* document ordering (>>, <<) on each document
- The document node precedes all others.
- Parents precede children.
- Children are ordered.
- Namespaces precede attributes, attributes precede children.
Note that the axes do not provide map 1:1 with the different
relations that appear in a formal description.
The parent and child axes are
inverses (for elements). The ancestor and
descendant axes are their transitive closures.
For sibling order, however, we have the closures
(following-sibling and
preceding-sibling) but not their transitive
reductions.
For document order, we have closures (following and
preceding) on element order (a) no transitive
reductions,
and (b) no named axes for node order as distinct from
element order.
XPath long syntax: simple
- child::para
- child::* (all element children)
- child::text() (all text node children)
- child::node() (all children)
- attribute::name
- attribute::*
- descendant::para
- ancestor::div
- ancestor-or-self::div
- descendant-or-self::para
Long syntax: more complex
- self::para (context node if para, otherwise nothing)
- child::chapter/descendant::para
- child::*/child::para (all para grandchildren)
- /
- /descendant::para (all para elements in the document)
- /descendant::olist/child::item
Long syntax: predicates
- child::para[position()=1]
- child::para[position()=last()]
- child::para[position()=last()-1]
- child::para[position()>1]
- following-sibling::chapter[position()=1]
- preceding-sibling::chapter[position()=1]
- /descendant::figure[position()=42]
- /child::doc/child::chapter[position()=5]/child::section[position()=2]
- child::para[attribute::type="warning"]
- child::para[attribute::type='warning'][position()=5]
- child::para[position()=5][attribute::type="warning"]
- child::chapter[child::title='Introduction']
- child::chapter[child::title]
- child::*[self::chapter or self::appendix]
- child::*[self::chapter or self::appendix][position()=last()]
Assignments (1)
No theory without practice.
- Make an XML version of your document using text/richtext or text/enriched. Because neither of these is defined by a schema, your document need not be valid, but you should try to make it correct against the spec. Note in XML comments any questions that arise about what does and doesn't count as correct against the spec.
- Check your Bare Bones TEI document against the DTD. Is it valid? If not, make it valid. Submit a valid Bare Bones document.
- For Bare Bones TEI and the text/richtext and/or text/enriched vocabularies of RFC 1341 and RFC 1896, answer the recurrent document-design questions (slides 11, 16, and 20-27 of today's slides). Find the answers either by consulting the spec(s) or by trying things against the DTD (if there is one).
Due: Sunday morning 16 September 2012.
Assignments (2)
No practice without context.
-
Imagine a document collection that might plausibly include your
document.
- Describe that collection and one or more of the audiences it might serve.
- Identify one or more things the audience might want to do with documents from the collection (reading them is one thing; are there others?).
- Identify some parts of the document that will need special treatment when that happens. What is that special treatment?
- Identify some ways (say, between three and fifty) in which members of audience might want to search for documents in the collection, or for locations in the documents.
Due: Sunday morning 16 September 2012.