Markup semantics and the preservation of intellectual content
The data curator reads Ecclesiastes
C. M. Sperberg-McQueen
Urbana, 20 May 2009
Confessions, disclosures, warnings
- radicals and responsibles
- IANAL (BSOMBFAL)
- texts ≠ books
- texts and images
- literature, language, text representation, markup, validation
What are we talking about here?
When we talk about curating humanities data,
what kinds of data do we mean?
What I'm talking about
When we talk about curating
humanities data,
what kinds of data do we mean?
- editions of works (e.g. Moby Dick, The Electronic Beowulf)
- editions of authors (e.g. Collected Works of Thomas Middleton)
- archives of an author, movement, theme, with (extensive) ancillary material
(e.g. The Blake Archive, Der junge Goethe)
- exhaustive corpora of a language and period (Anglo-Saxon Poetic Records,
Thesaurus Linguae Graecae,
Trésor de la langue française, ...)
- dictionaries (e.g. the Diction of Old English or
the Dictionary of the Old Spanish Language), with ancillary materials [see corpora])
- modern corpora for linguistic work, with annotation (Penn TreeBank,
Brown Corpus, Lancaster-Oslo/Bergen corpus, Corpus of London Teenage Language (COLT),
British National Corpus (BNC),
TIGer (Trees in German), ...)
- corpora for historical dictionaries (DOE, DOSL, Thesaurus Linguae Latinae Hiberniae)
- art-historical slide collections
- 3-D reconstructions (e.g. the Chicago Columbian Exposition, the Crystal Palace, ...)
- raw and digitally enhanced page images of an important manuscript
(e.g. the Beowulf manuscript)
- A suite of Fortran programs that generate fugues; a set of fugues written by
those programs (a) in the program's output notation, (b) in synthesized sound, (c) as recorded
by the school's chamber orchestra
- A rhyme database covering verse of a particular author / language / period
- A set of dialect maps
- Transcriptions of field-linguists' informant interviews
- Important programs
N.B. this is not quite the same field as defined by Palmer and Craigin.
SHRDLU: an instructive example
1968-70, MIT: Terry Winograd writes
SHRDLU, a milestone in the history
of artificial intelligence, natural-language processing, and cognitive science.
The source code is available.
But apparently can't be run today: it's mostly in MicroPLANNER.
Various reconstructions are available.
Which is to be preserved, made accessible, curated?
Books are for use
-S. R. Ranganathan, Five Laws of Library Science (Madras, 1931)
Does this apply to data?
If not, why not? If so, what are the implications?
What constitutes the book?
What is it that you want to use? What is it you want to preserve for the user?
Typography?
Chemical composition?
Manufacturing process?
Marginalia?
Intellectual content?
Linguistic content? (To wit ... ?)
How long do things last?
How old is the average artefact studied by a humanist?
How old is the average secondary literature consulted by a humanist?
How old is the average software package in use today?
Emulation, migration, normalization
- emulation: keep the original data / software,
emulate (i.e. fake) the environment?
- migration: when the original object is in
danger of obsolescence, translate it into a newer equivalent.
- normalization: on ingestion, translate the
object into a stable non-proprietary form. Cf. ICPSR's (past)
use of Osiris.
Which approach, when?
Do digital objects suffer generational degeneration?
Second-generation photocopies are less clear.
Ditto second-generation photographs, copies of drawings,
manuscript transcriptions of texts.
Are digital objects free of this degeneration?
Yes, digital objects suffer generational degeneration
Straight copies are usually exempt.
Every format conversion involves a better or worse match;
most are potentially lossy.
Every reader [their] book
Every reader [their] book.
-Ranganathan, Law 2
How do you achieve this for books / traditional media?
How could you achieve this for digital materials? Are there things
you can do for digital that you can't do for paper?
What would you have to have in order to achieve this for digital materials?
Every book its reader
-Ranganathan, Law 3
How do you achieve this for books / traditional media?
How could you achieve this for digital materials?
What would you have to have in order to achieve this for digital materials?
Documentation, documentation, documentation
Metadata.
Inline? Yes, please! Remember the help desk.
Stand-off / external? Yes, please! Remember the catalog manager.
For printed books (non-incunabula) we have metadata
both inline and externally. Is this a problem?
Information discovery begins at Google
Within the next five years, all information discovery will
begin at Google, including discovery of library materials.
The continuing disaggregation of content from its original container
will cause a revolution in resource discovery.
-Taiga Forum Provocative Statements, 10 March 2006
Is this true?
Should it be?
Are there alternatives?
Save the time of the reader
Save the time of the reader.
-Ranganathan, Law 4
Does this relate to data curation at all?
Does saving the time of the data curator count, indirectly?
When automation turns bad
<dublin_core>
<dcvalue element="contributor" qualifier="none"
>Scanning, indexing, and description
sponsored by the Illinois State Library and
the University of Illinois at Urbana-Champaign
Library. Geo-referencing sponsored and
performed by the Geographic Modeling Systems
Laboratory, University of Illinois at
Urbana-Champaign.</dcvalue>
<dcvalue element="contributor"
qualifier="author"
>United States.
Agricultural Adjustment Agency.</dcvalue>
<dcvalue element="contributor"
qualifier="author"
>Aerial Photographs</dcvalue>There appears to be an error here (“Aerial Photographs”
is apparently not the corporate or individual name of an author
of this photograph).
Can this be avoided?
How did this happen?
Dubin explains:
An obvious interpretation is that this is simple
tag abuse or human error, but the history of this description reveals
it to be an example of a more general and complicated problem. This is
the latest in a series of descriptions each derived from an earlier
version:
- A paper description accompanied the original photograph, which had been taken in 1938.
- In 1998 the photograph was scanned for inclusion in an image database made available on the web [grainger99]. A metadata record for the photograph was entered into a relational database. The fields for that database were derived from the FGDC [Federal Geographic Data Committee] Content Standard for Digital Geospatial Metadata [fgdc98].
- In May of 2005 an OAI 2.0 metadata record was derived from that database entry, via a mapping from the database fields into Dublin Core.
- Several months later the OAI record was transformed via XSLT [XSL Transformations] into a form suitable for ingestion into a DSpace installation.
- When the record was exported from DSpace, additonal DC [Dublin Core] metadata statements had been automatically added.
Verifying emulation, migration, normalization
How do you know when an emulator is working correctly?
How do you know when a migration program has produced a correct result?
How do you detect errors in migration?
Methods of verification and quality control
Naked human eyeballs.
Automated processes:
- validation
- supravalidation
- false-color proofs
Semi-automated human intervention (padded cells).
The 1, 10, 100 practice.
Formal methods of verification?
- Identify the meaning of old record.
- Identify the meaning of new record.
- Compare.
- Same? ⇒ OK.
- Different? ⇒ NOT OK.
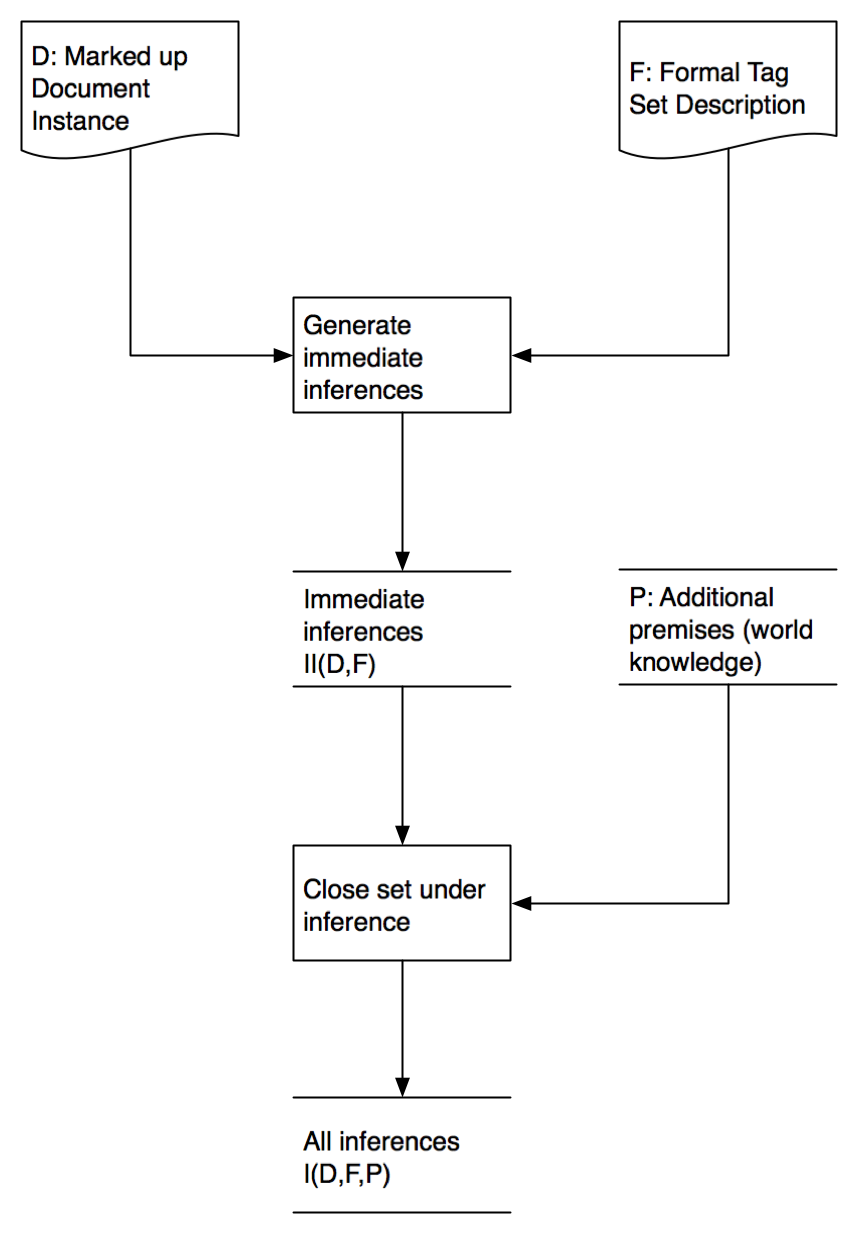
Identifying the meaning of markup
For each construct, define skeleton sentences
in (English or) symbolic logic.
Skeleton sentences can contain blanks.
For each blank, a deictic expression
says how to fill it in.
For each instance of the construct,
generate an instance sentence from each skeleton sentence.
Optionally generate further inferences.
Identifying the meaning of markup
A simple example
From a
formalization
of the OAI-PMH vocabulary:
- oai2:OAI-PMH
-
(∃ q : OAI-request)
(∃ r : OAI-response)
(∃ s : OAI-server)
(∃ t : moment)
( q = (℩ q : OAI-request)(models({ ./oai:request }, q))
∧ s = (℩ s : OAI-server)(uri_server({ string(./oai:request) }, s))
∧ t = (℩ t : moment)(xsd_lv(xsd:dateTime, { string(./oai:responseDate) }, t))
∧ (∀ x)(uri_server(x, s) ⇒ x = { string(./oai:request) })
∧ { . } = r
∧ served_response(q,s,t,r)) - oai2:error
- (∃ q : OAI-request)
(models({ preceding-sibling::oai:request }, q)
∧ invalid(q)
∧ request_error(q, { string(@code) })
∧ ({ string(.) } ≠ "" ⇒ error_nldesc(q, { string(.) }) )
)
)
- oai2:GetRecord
- (∃ q : OAI-request)
(∃ s : oai-server)
(∃ d : string)
(∃ i : oai-item)
(∃ p : string)
(q =
(℩ q : OAI-request)(req_resp(q,{ ancestor::oai:OAI-PMH }))
s =
(℩ s : oai-server)(resp_server({ ancestor::oai:OAI-PMH }, s))
d =
(℩ d : string)(request_identifier(q, d))
i =
(℩ i : oai-item)(item_id(i, d))
p =
(℩ p : string(p)(request_metadataPrefix(q, p))
∧ request_verb(q, "GetRecord")
∧ errorfree(q)
∧ isin_repository_item(s, i)
∧ hasformat_repository_item_format(s, i, p)
)
If you can't prevent degeneration, detect it
Before: ...
After: ... (∃ p)((person(p) ∨ organization(p)
∧ name(p,“Aerial photographs”) ...
Is there a reason these are different?
The library is a growing organism
The library is a growing organism.
-Ranganathan, Law 5
Is this true w.r.t. digital materials? Illlustrate.