What does descriptive markup contribute
to digital humanities?
C. M. Sperberg-McQueen, Black Mesa Technologies LLC
26 October 2015
http://blackmesatech.com/2015/10/KIaCiDH/

Introduction
Basic decisions about the information or substantive value of any document rendered in a digital substrate ... are fraught with theoretical implications.-Johanna Drucker
Let me write a nation's data structures, and I care not who writes its code.-Richard Ristow
The elevator pitch
- is not value-free or value-neutral;
- offers a compelling account of the nature of text;
- provides a helpful foundation for better software;
- leaves room for further development.
Theses
Documents have structure
The kind of structure varies with the kind of document. But: books, cantos, lines; acts, scenes, speeches, lines; treaty, clause; ...
Surprisingly, this was historically non-obvious.
Predefined primitives
Therefore users must be allowed to define their own sets of basic notions (in XML: their own element types, attributes).
Formally, SGML and XML define metalanguages; it is users who define the actual markup languages like HTML or TEI.
Longevity
- application-independent
- vendor-neutral
Some consequences
- Application-independence seems to require open standards.
- Reusability improves when different things are represented differently, similar things similarly.What things are similar, how? This leads us directly into ontology.
- Declarative semantics make it possible to reason about representations; imperative semantics impede.
N.B. SGML and XML were defined by people who wanted to make reusable documents using declarative descriptive semantics; they enable these practices but cannot by themselves enforce them.
Validation
- verification
- validation
Document grammars
This intertwining of grammar, tree, XML (validation method, data structure, serialization format) very powerful.
An objection
Trees
The requirements of XML were such that only a single hierarchy could be imposed on (actually inserted into) a document. This meant that scholars migrating mterials into electronic form frequently faced the problem of choosing between categories or types of information to be tagged. ... Did one chunk a text into chapters or into pages? One could not do both, since one chapter might end and another begin on the same page, in which case the two systems would conflict with each other.
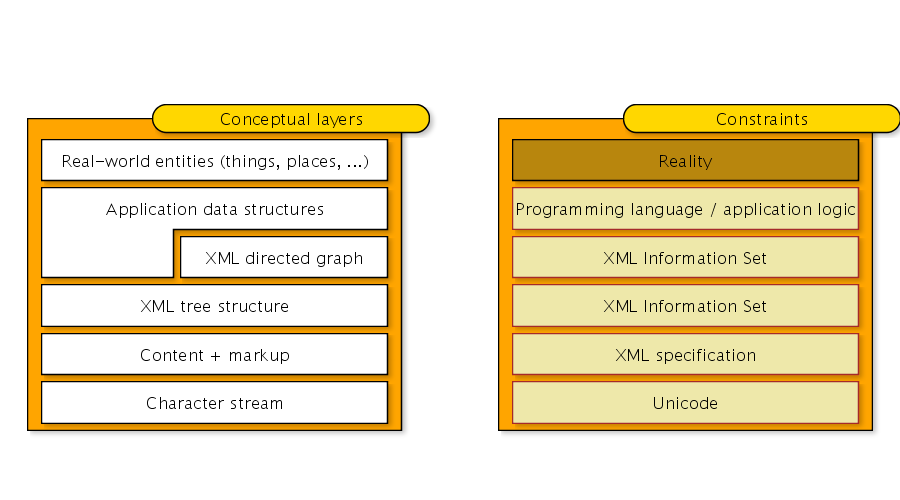
Character sequences, trees, graphs
I think they oversimplify.
SGML and XML documents are graphs
Other data structures
- ignore parts of the document (projection)
- interpret arcs appropriately
- restructure as needed
SGML and XML have several models
What does handle mean?
Representation
- Each property and value we distinguish in the data can be distinguished in the representation.
- For each operation we wish to perform on the data, there is a corresponding operation the machine can perform on the representation, which produces an appropriate result.
Properties and operations on trees
- Type and attributes of node.
- Given parent, identify children (and vice versa).
- Given object, identify siblings.
- Create / update / delete subtree.
- Delete node and promote children.
- Insert new node above specified children.
- ...
Representing hierarchies
- CONCUR (ISO 8879), XCONCUR (Schonefeldt).
- Standoff markup (Thompson, many others).
- Virtual elements (TEI).
- Milestone elements (TEI and folklore).
- Trojan Horse markup (DeRose, generalization of milestones).
Bias
The choice
- use XML
- invent an alternative
Ontological commitments
What now?
Perhaps permanent?
- Texts have structure.
- User self-determination.
- Vendor-independence.
- Declarative descriptive semantics.
- Validation.
Permanently precarious?
- New universal vocabularies abound.
- Vendors never object to lock-in.
- For new apps, imperative semantics are easier and simpler.
- Openness, application-independence, vendor-independence, and documentation are a lot of trouble.
Forward?
- Can we find better ways to interact with programming languages?(a) better APIs? (b) programming-language friendlier markup? (c) better programming languges?
- Can we find better ways to document tag sets?
- Can we find better data structures?(character ranges, Goddags, Rhine Delta graphs, other graphs)
- Can we find better validation mechanisms?(Predicate-based validation, rabbit/duck grammars, Creole, graph grammars)
- Can we use markup better in our real work?
Thank you
Acknowledgements
- Photo: Detail from Black Mesa, by Marcin Wichary, 9 September 2008 (CC BY 2.0)